AnKi’s GPU memory management system was introduced alongside Vulkan nine years ago, but the transition to GPU-driven rendering and the introduction of a render-graph fundamentally changed the way GPU memory is handled. In this blog post we will look at how the system evolved over the years and as a bonus compare memory statistics across GPUs from different vendors. As always: Whatever you read here does not represent my current or future employers.
When Vulkan was first introduced into AnKi, the engine still followed a fairly traditional rendering pipeline. Everything was composed from buffers and textures. Meshes owned their vertex and index buffers, materials owned their textures, and the renderer itself maintained additional buffers and textures for its own needs.
At the time, the graphics API abstraction layer (or RHI as some engines call it) managed memory by allocating large VkDeviceMemory chunks and suballocating resources from them. The allocator was entirely custom built since Vulkan Memory Allocator (VMA) did not yet exist and because writing memory allocators is a fun way to pass the time. So a custom allocator it was.
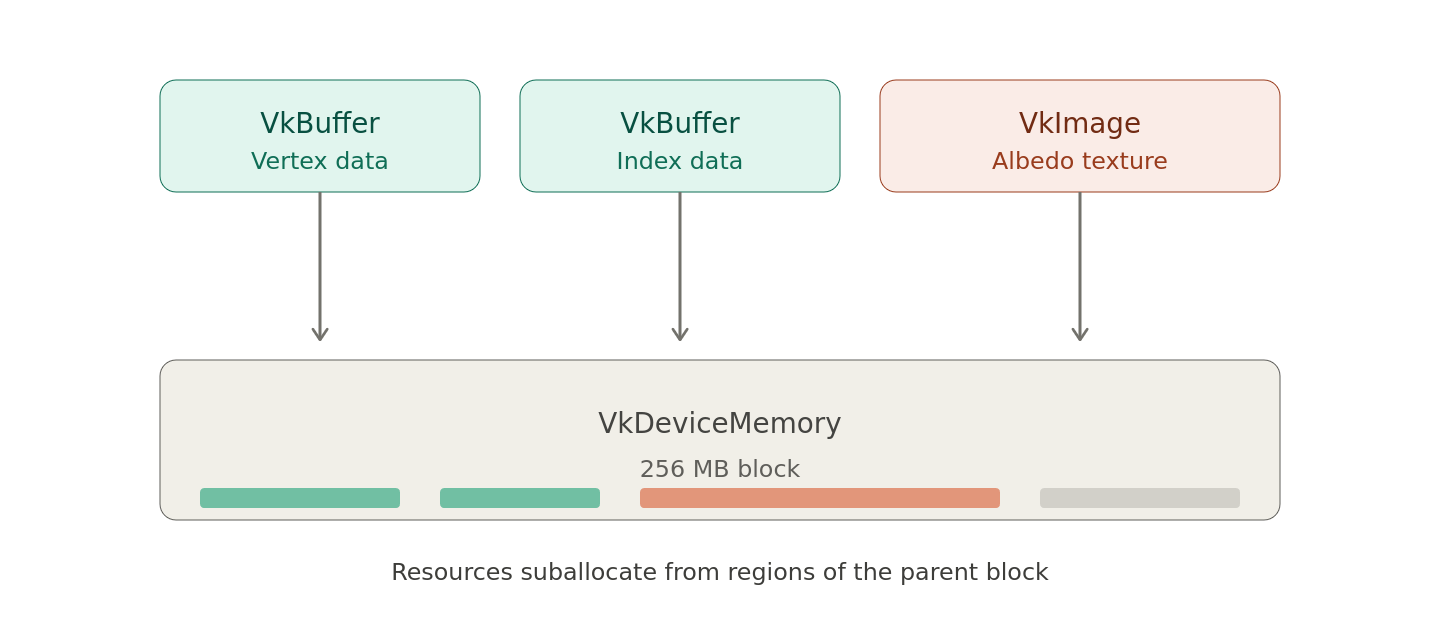
On top of that, the engine used a number of global buffers to hold frame transient data. For example, all draw calls allocated their uniform data from a single large uniform buffer. On top of that uniform buffer there was a linear allocator and memory was recycled after N frames. To write that differently, AnKi’s Vulkan backend was suballocating VkDeviceMemory for that global uniform buffer and every drawcall was suballocating out of this uniform buffer.
When AnKi introduced GPU-driven rendering a few things had to change. For reasons explained in this video presentation, all vertex and index data had to be moved into a single VkBuffer. Individual buffers were no longer an option. That change required a more generic allocator capable of managing allocations within a fixed block of memory. To solve this I introduced something like a “two level segregated fit” (TLSF) allocator that suballocated memory from a global geometry buffer. Unlike the lower-level Vulkan memory allocator, this allocator was not part of the graphics API abstraction layer because it didn’t need to be.
Managing memory for the render-graph required a similar approach. The render-graph creates a large number of transient textures many of which can be recycled even within the same frame. Supporting this required several enhancements to the TLSF allocator but the biggest change was in the way textures were created.
Using D3D terminology, the graphics abstraction gained support for both “placed” and “committed” textures. Previously, textures were always “committed” and the graphics backend internally “placed” them into a region of VkDeviceMemory. With the new system texture initialization can also accept a buffer and an offset describing where the texture should be “placed” inside that buffer. A similar change was made for acceleration structures, which became “placed”-only resources.
At this point, the system had evolved from a model where the graphics API abstraction handled almost all GPU memory allocations into a hybrid approach where some allocations were managed by the abstraction and others directly by higher-level engine code. The only resources still relying on the graphics abstraction’s allocator were material textures and a few persistent renderer resources. Everything else had already moved onto larger shared buffers managed externally. The writing was on the wall. All memory allocations had to move outside the graphics API abstraction. And that is exactly what happened.
The graphics API abstraction no longer performs suballocations from VkDeviceMemory. When the engine requests a 32 MB buffer, the Vulkan backend allocates exactly 32 MB of VkDeviceMemory (including any required alignment padding) and binds it directly to the buffer. The same approach applies to “committed” textures. If the texture is “committed” the Vulkan backend will allocate the exact size requested by vkGetImageMemoryRequirements. But textures can also be “placed” as we mentioned above.

At the moment we have the following buffers with their associated allocator. Some allocators are TLSF-based and others are linear:
- Unified Geometry Buffer: All geometry data are stored in that buffer.
- Texture pool: All material textures go there.
- GPU scene: All the GPU visible scene data are stored there.
- Rendergraph memory: This holds the transient rendergraph data.
- Renderer’s memory: This holds persistent renderer resources. This is mostly textures that need to stay persistent across frames. One example is the history buffer used in TAA.
- ReBAR memory: Used by the renderer to store uniform data. Its usage is pretty limited at the moment.
- … some other misc buffers
Memory consumption across GPUs
In this section, we use statistics provided by the memory allocators to measure the memory consumption of the largest memory pools and compare GPUs from different vendors. For this analysis, I used the three devices currently available to me: an Android phone with an Arm Mali-G715 GPU, a desktop system with an nVidia GPU running Linux, and the integrated GPU included with my AMD processor. The AMD integrated GPU runs on top of the open-source Mesa driver stack (RADV).
The results are both boring and interesting at the same time. All values shown are percentages.
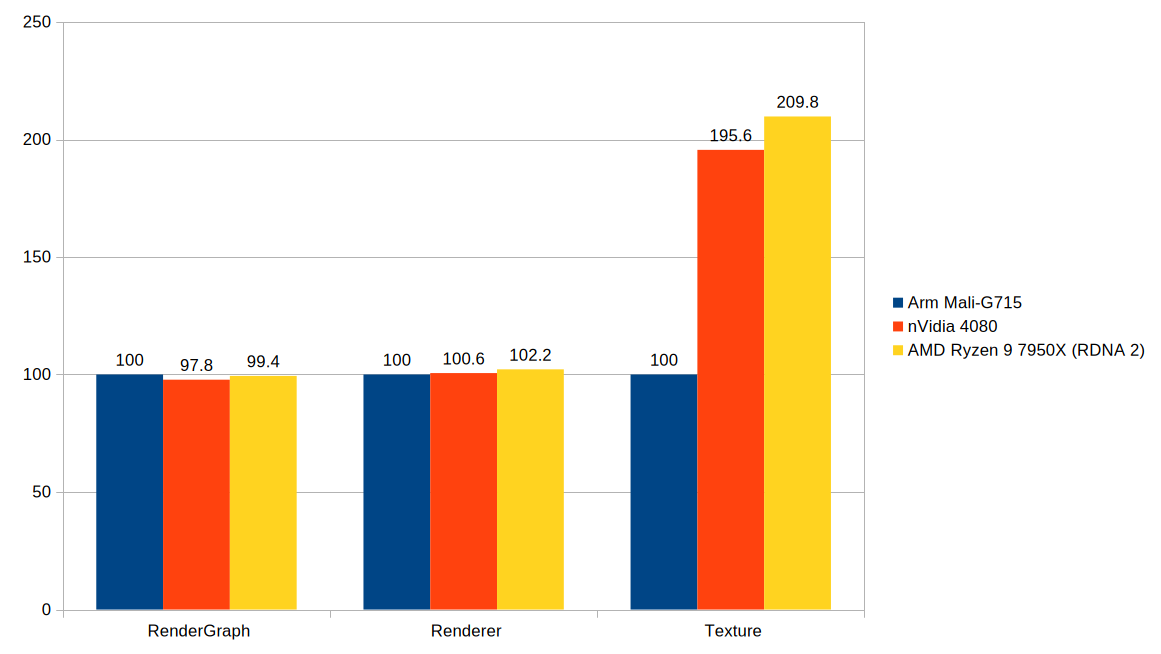
For the render-graph and renderer memory pools the memory consumption is almost equal across vendors. AMD consumes slightly more than nVidia but not by allot.
Things become more interesting when looking at the memory required for standard block-compressed textures (right three bars). On Android, AnKi compresses textures using ASTC with 8×8 blocks, while the nVidia and AMD GPUs use the traditional BC formats with 4×4 blocks. In theory, 8×8 blocks provide lower image quality than 4×4 blocks, but the roughly 50% reduction in memory usage is, in my opinion, well worth the tradeoff. Asset streaming is a real issue in modern games causing immersion breaking stutters. At the same time we have RAM prices still extremely high at the time of writing. If we take into account these two issues ASTC’s proposition is hard to ignore.